
AI OCRによるPDFからExcelへの変換業務
◆背景:
PDF帳票の内容をExcelへ転記する作業は、現在でも多くの企業で手間のかかる業務の一つです。
特にスキャンPDFや帳票PDFでは、必要な情報を読み取り、Excelへ入力するまでに多くの時間がかかります。
対象となる帳票の例は以下のとおりです。
- 見積書
- 資材表
- 数量表
- 請求書
- 会計関連資料
これらのPDFを手作業でExcelへ入力する場合、以下のような課題が発生します。
- 入力作業に時間がかかる
- 転記ミスが発生しやすい
- 大量の資料を短時間で処理することが難しい
また、従来のOCRだけでは、実際の業務でそのまま利用できる精度を出すことが難しいケースも多くあります。
例えば、以下のような問題が発生します。
- 表の構造を正しく認識できない
- 行を誤って結合してしまう
- 列を正しく分割できない
- 数値を誤認識してしまう
- 複数行データのフォーマットが崩れる
さらに、日本語の帳票では以下のような要素があるため、難易度が高くなります。
- スキャン品質が低いPDFがある
- 縦書きと横書きが混在している
- 複数の表が含まれている
- レイアウトが固定されていない
- 「㎡」「m³」「▲」などの特殊文字を個別に処理する必要がある
◆解決策:
これらの課題を解決するため、TTMではAI Vision Modelを活用し、PDF内の表データをExcelへ自動変換するAI OCRシステムを構築しました。
1.使用した技術スタック
- 開発言語:Python 3.x(パイプライン全体の処理)、およびVB.NET(画面インターフェース層)
| コンポーネント | ライブラリ・サービス | 役割 |
| PDF render | PyMuPDF (fitz) | PDFを高品質なPNG画像へ変換 |
| Image processing | OpenCV, Pillow | 画像の回転補正、罫線強調 |
| OCR orientation | pytesseract (OSD) | 画像の回転角度を検出 |
| AI Vision | OpenAI GPT-4o-mini | 表データを抽出し、CSV形式へ変換 |
| AI Vision (alt) | Google Gemini 2.5 Flash | 表データを抽出し、CSV形式へ変換 |
| Excel output | openpyxl | Excel出力とスタイル設定 |
| Design pattern | Strategy + Factory | 会社ごとの処理ロジックを切り替え |
2.処理フロー
AI OCRシステムは、主に以下の5つのステップで構成されています。

ステップ1:PDFを高品質な画像へ変換
最初に、PDFをAIモデルが読み取りやすい画像形式へ変換します。
PDF内の小さな文字や表の罫線まで正しく認識させるため、PyMuPDF(fitz)を使用し、zoom factorを4倍に設定して画像化しました。
これは約288 DPI相当の解像度です。
実際の検証では、72〜150 DPI程度の低い解像度では、日本語の似た形の文字や細かい数値をAIモデルが誤認識しやすい傾向がありました。
一方、288 DPI程度まで解像度を上げることで、文字の認識精度が大きく改善されました。
ステップ2:画像の前処理
APIへ画像を送信する前に、画像の前処理を行います。主な処理は以下の2つです。
2-1. 画像の自動回転補正
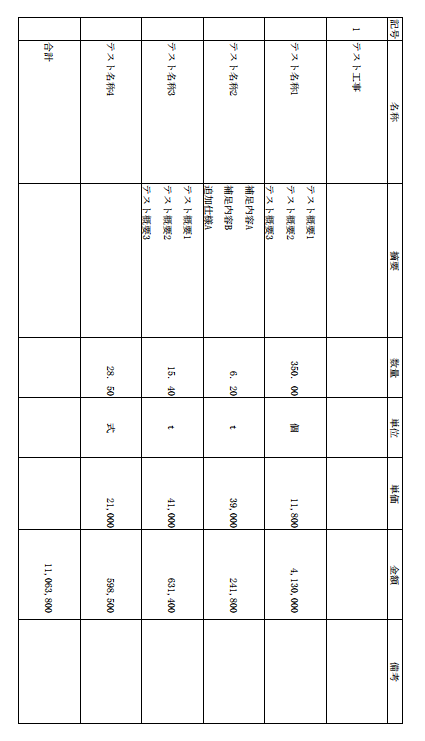
PDFによっては、ページの向きが正しく保存されていない場合があります。
そのため、Tesseract OSD(Orientation and Script Detection)を使用して画像の向きを検出し、正しい方向へ自動補正しました。
| 元のPDF | AIに送信する画像 |
 |
 |
2-2. 表の罫線強調
スキャンPDFでは、表の罫線が薄い、途切れている、または不均一になっていることがあります。
そこで、OpenCVのmorphological operationsを使用し、横罫線・縦罫線を強調しました。
ステップ3:日本語帳票向けのPrompt Engineering
モデル別のプロンプト設計
GeminiとGPTではOCR/Vision処理の特性が異なるため、各モデルごとにプロンプトを分けて管理し、調整・保守しやすい構成としました。
この工程は、最もチューニングに時間を要した部分です。
実際の開発を通じて得られた、プロンプト設計上の主なポイントは以下のとおりです。
| 課題 | プロンプトでの指示 | 理由 |
| 「▲」の扱い | 「-」に変換する | 特定帳票の処理ルールに合わせるため |
| 「、」の扱い | 「,」と誤認識しないようにする | CSV構造が崩れることを防ぐため |
| 「m³」「㎡」などの単位 | Unicode文字のまま保持し、「m3」などに変換しない | 帳票上の単位表記を正しく保持するため |
| 小数点以下の表記 | 「480.00」などを省略せず、そのまま保持する | AIが数値を自動的に簡略化してしまうことを防ぐため |
| 2つの数値の間にある点線 | 「.」として表現する | 日本の見積書・積算表における表記ルールに対応するため |
| 表外の文字 | 実際の位置に合わせて、表の前後に出力する | ページ番号などが表データの途中に入ることを防ぐため |
ステップ4:CSVデータのクレンジングと標準化
AIが出力したCSVデータは、そのままExcelに書き込めるとは限りません。
例えば、数量・単価・金額などの列では、AIが「56000」や「3,454」といった値を文字列として返す場合があります。
この状態のままExcelへ書き込むと、Excel上では数値として扱われず、テンプレート側で設定されている通貨形式や小数点形式が正しく反映されません。
そこで、数量・単価・金額などの対象列を判定し、文字列から数値型へ変換してからExcelへ出力するようにしました。
これにより、Excel側のセル書式(FormatCell)が正しく適用されるようになります。
また、帳票や顧客ごとの要件に応じて、以下のような処理も行います。
- 列の分割
- 列の結合
- 必要な列の追加
- 特殊な文字・記号の変換
- 出力形式の統一
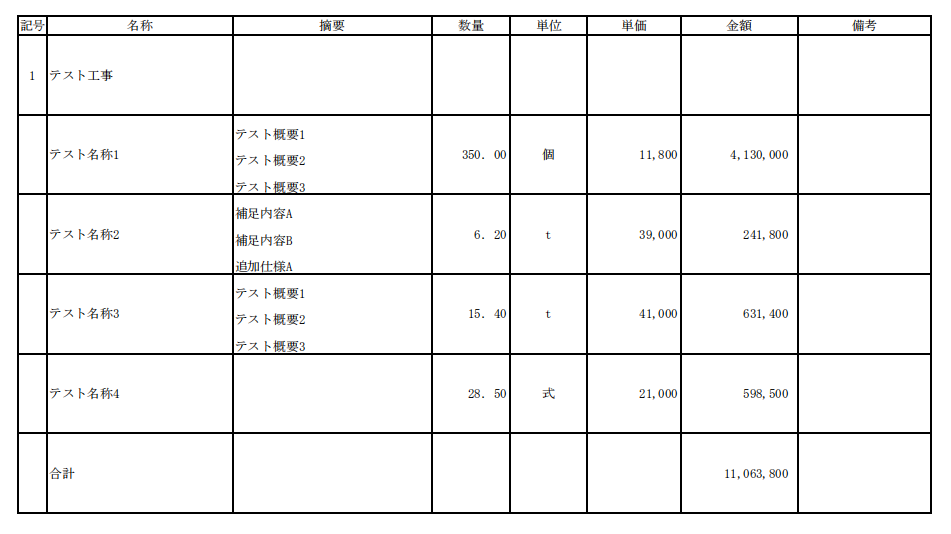
ステップ5:Excel出力
最後に、標準化したデータをExcelへ出力します。
本システムでは、単にテキストをExcelへ書き込むだけではなく、実際の業務でそのまま利用できるExcelファイルを生成することを目指しました。
Excel出力時には、以下のような処理を行っています。
- データを正しい行・列に出力する
- 各セルのalignmentを調整する
- データ範囲全体にborderを設定する
- 外枠と内側の罫線を設定する
- 必要に応じてセル結合を行う
- 1つのセル内にある複数行データを保持する
- 1つのworksheet内に複数の表を分けて出力する
◆実際に得られた効果
- 標準的な帳票の表データでは、約95%の精度でデータを抽出できました。
- さらに、手入力と比較して、処理時間を大幅に短縮することができました。


